A dog house must be built for your new dog. The necessary materials have been provided to you: a hammer, nails, wooden boards, and a blueprint for the dog house. The hammer in placed in charge. It will summon you to perform tasks on its behalf, such as nailing wooden boards together, verifying that the dog house is being built according to the blueprint, and so on.Here, the task of building a dog house represents the task of performing functional verification, the blueprint represents the specification, and the hammer represents the simulator. This scenario is both unpleasant and counter-intuitive because the power to build the dog house has been placed at the wrong level: the hammer is but a mere tool, whose sole purpose is to drive nails; it is unconcerned with the larger task of building a dog house. Thus, the more logical approach would be to grant you the power to build the dog house because you are (1) genuinely concerned with the task of building a dog house and (2) capable of utilizing all provided materials firsthand, whereas the hammer required you to perform tasks on its behalf. Likewise, the simulator is but a mere tool, whose sole purpose is to simulate an instantiated Verilog module, that is unconcerned with the larger task of performing functional verification. Thus, the more logical approach would be to grant you the power to perform functional verification. However, due to the overwhelming complexity of hardware designs undertaken today, it is both impractical and error-prone for a human to perform functional verification manually. For this reason, executable specifications-which are, in essence, a combination of the blueprint (the rules for building a dog house) and yourself (the entity capable of following the blueprint and interacting with all provided materials to build the dog house)-are commonly used to perform functional verification instead.
#include <stddef.h>
#include <pthread.h>
#include <vpi_user.h>
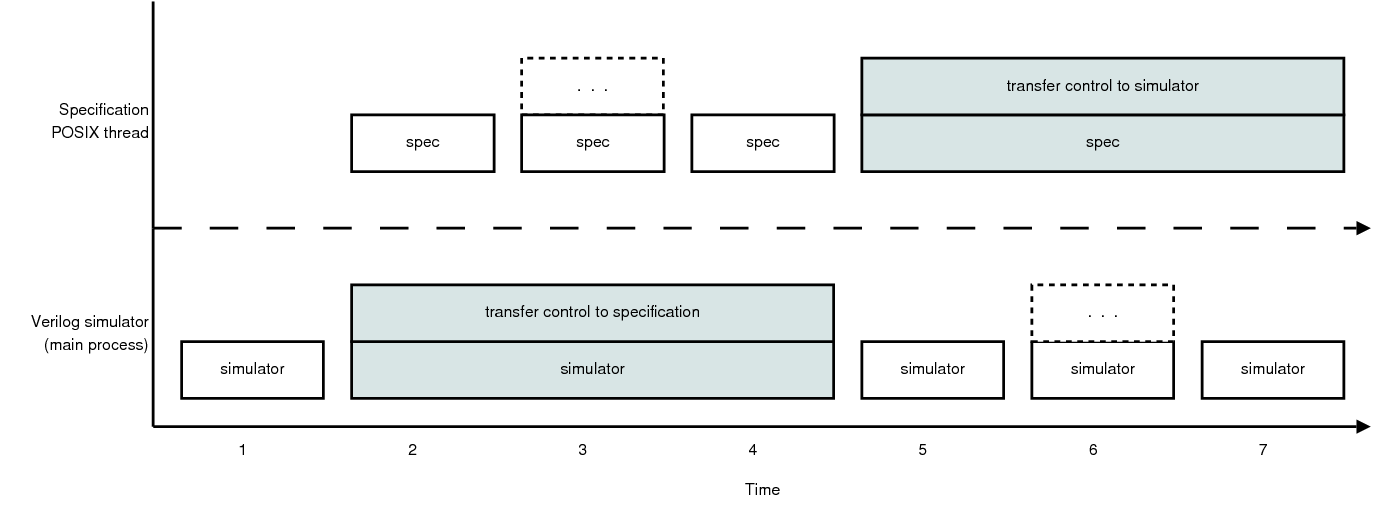
void* spec_run(void* dummy) {
/* 1. schedule a callback to relay_spec();
2. invoke relay_sim();
3. repeat */
return NULL;
}
pthread_t specThread;
pthread_mutex_t specLock;
pthread_mutex_t simLock;
PLI_INT32 relay_init(p_cb_data dummy) {
pthread_mutex_init(&specLock, NULL);
pthread_mutex_lock(&specLock);
pthread_mutex_init(&simLock, NULL);
pthread_mutex_lock(&simLock);
/* start the specification thread */
pthread_create(&specThread, NULL, spec_run, NULL);
pthread_mutex_lock(&simLock);
return 0;
}
/* Transfers control to the specification. */
void relay_spec() {
pthread_mutex_unlock(&specLock);
pthread_mutex_lock(&simLock);
}
/* Transfers control to the Verilog simulator. */
void relay_sim() {
pthread_mutex_unlock(&simLock);
pthread_mutex_lock(&specLock);
}
void startup() {
s_cb_data call;
call.reason = cbStartOfSimulation;
call.cb_rtn = relay_init;
call.obj = NULL;
call.time = NULL;
call.value = NULL;
call.user_data = NULL;
vpi_free_object(vpi_register_cb(&call));
}
void (*vlog_startup_routines[])() = { startup, NULL };
void verify_expectation() {
apply_stimulus();
simulate_design();
verify_response();
}
void verify_expectation() {
static enum {
stimulate,
simulate,
verify
} stage = stimulate;
switch (stage) {
case stimulate:
apply_stimulus();
stage = simulate;
break;
case simulate:
simulate_design();
stage = verify;
break;
case verify:
verify_response();
stage = stimulate;
break;
}
}
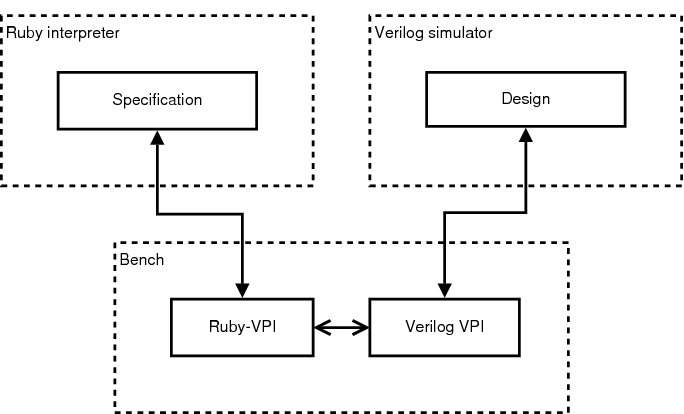
C code. C code run. Run code run. Please! -Cynthia DunningThe drudgery of using VPI through the C programming language and VPI's inherent dependence on simulator-driven functional verification were the primary factors that motivated the creation of Ruby-VPI. These factors, among others, are discussed in the following subsections.
An abstract program consists of conceptual constructs: operations, data types, sequences, and communication. The concrete machine program is concerned with bits, registers, conditions, branches, channels, disks, and such. To the extent that the high-level language embodies the constructs one wants in the abstract program and avoids all lower ones, it eliminates a whole level of complexity that was never inherent in the program at all.This argument strongly motivates and justifies the use of a higher level language, such as Ruby, in performing functional verification with Verilog VPI.
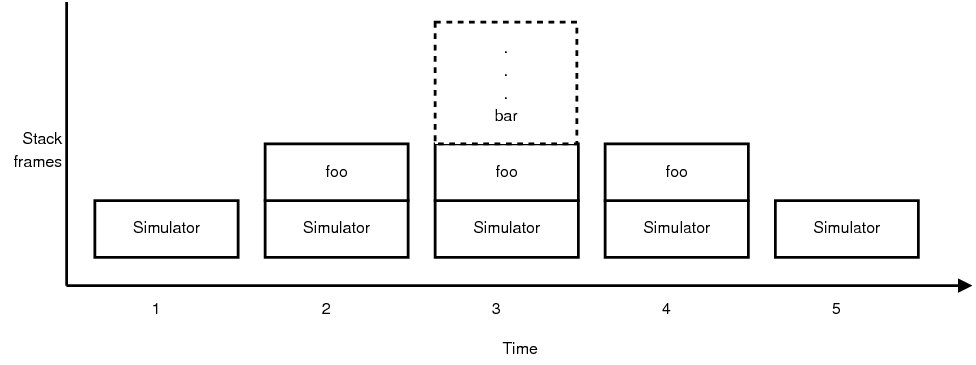
Quis custodiet ipsos custodes? -Juvenal, Satires, VI, 346-348A system task is composed of two C functions: calltf and compiletf [36,page 34 and 39]. The former is invoked whenever its associated system task is invoked, and the latter is invoked, only once, before the simulation begins [36,page 37]. Whereas the calltf function defines verification logic for a system task, the sole purpose of the compiletf function is to verify that its system task, and thereby its associated calltf function, is invoked correctly [36,page 37]. For example, it checks whether (1) the number of arguments passed to its system task, and (2) the types of those arguments are correct [36,page 37]. This situation resembles the ancient, recursive dilemma quis custodiet ipsos custodes? or who guards the guardians? by which, the compiletf function procures a mere illusion of increased correctness while inadvertently sacrificing ease of development, as compiletf functions must be written and maintained alongside every system task that performs verification.
He draweth out the thread of his verbosity finer than the staple of his argument. -William Shakespeare, Love's Labour's Lost, 5:1Because the C programming language is a high level language, i.e. one level of abstraction higher than assembler, it seems verbose in comparison to very high level languages such as Ruby. This verbosity of expression necessitates increased effort to perform even the most basic of tasks. For example, consider the expressions shown in figures 5.2 and 5.3. Both determine whether all registers associated with a module, whose handle is stored in the some_module variable, presently have a logic value that is greater than one when accessed in integer form. The result of each expression is ultimately stored in the result variable. Notice how the Ruby expression captures the intent of our task in a clear, concise manner. It seems to read out loud: "the result is whether some module has all registers such that each register has an integer value greater than one". In contrast, the C expression mechanically orchestrates our task, more so than reflecting our intent, in painstaking detail. It seems to drone: "assume result true; declare local variables; iterate over registers; read integer value; check integer value; adjust result; free iterator..." ad nauseam.
int result = 1; /* true */
s_vpi_value wrapper;
vpiHandle reg;
vpiHandle iterator = vpi_iterate( vpiReg, some_module );
while (reg = vpi_scan( iterator )) {
wrapper.format = vpiIntVal;
vpi_get_value( reg, wrapper );
if (wrapper.value.integer <= 1) {
result = 0; /* false */
vpi_free_object( iterator );
break;
}
}
$ generate_test.rb foo.v --name bar module foo create foo_bar_runner.rake create foo_bar_bench.v create foo_bar_bench.rb create foo_bar_design.rb create foo_bar_proto.rb create foo_bar_spec.rb
#include <stdarg.h>
void foo(va_list ap) {
va_list *p = ≈
}
| Accessor | Kind of value accessed | VPI functions used to access the value |
| d | delay | vpi_get_delays and vpi_put_delays |
| l | logic | vpi_get_value and vpi_put_value |
| i | integer | vpi_get |
| b | boolean | vpi_get |
| s | string | vpi_get_str |
| h | handle | vpi_handle |
| Operation | _ | Property | _ | Accessor | Addendum |
| optional | required | optional | |||

module counter #(parameter Size = 5) ( input clock, input reset, output reg [Size - 1 : 0] count ); endmodule
$ generate_test.rb counter.v --rspec --name rspec module counter create counter_rspec_runner.rake create counter_rspec_bench.v create counter_rspec_bench.rb create counter_rspec_design.rb create counter_rspec_proto.rb create counter_rspec_spec.rb
$ generate_test.rb counter.v --xunit --name xunit module counter create counter_xunit_runner.rake create counter_xunit_bench.v create counter_xunit_bench.rb create counter_xunit_design.rb create counter_xunit_proto.rb create counter_xunit_spec.rb
# tight upper bound for counter's value
LIMIT = 2 ** Counter.Size.intVal
# maximum allowed value for a counter
MAX = LIMIT - 1
context "A resetted counter's value" do
setup do
Counter.reset!
end
specify "should be zero" do
Counter.count.intVal.should == 0
end
specify "should increment upon rising clock edges" do
LIMIT.times do |i|
Counter.count.intVal.should == i
simulate # increment the counter
end
end
end
context "A counter with the maximum value" do
setup do
Counter.reset!
# increment the counter to maximum value
MAX.times { simulate }
Counter.count.intVal.should == MAX
end
specify "should overflow upon increment" do
simulate # increment the counter
Counter.count.intVal.should == 0
end
end
# tight upper bound for counter's value
LIMIT = 2 ** Counter.Size.intVal
# maximum allowed value for a counter
MAX = LIMIT - 1
class ResettedCounterValue < Test::Unit::TestCase
def setup
Counter.reset!
end
def test_zero
assert_equal 0, Counter.count.intVal
end
def test_increment
LIMIT.times do |i|
assert_equal i, Counter.count.intVal
simulate # increment the counter
end
end
end
class MaximumCounterValue < Test::Unit::TestCase
def setup
Counter.reset!
# increment the counter to maximum value
MAX.times { simulate }
assert_equal MAX, Counter.count.intVal
end
def test_overflow
simulate # increment the counter
assert_equal 0, Counter.count.intVal
end
end
def Counter.reset! reset.intVal = 1 simulate reset.intVal = 0 end
def Counter.simulate! if clock.posedge? if reset.intVal == 1 count.intVal = 0 else count.intVal += 1 end end end
module counter #(parameter Size = 5) ( input clock, input reset, output reg [Size - 1 : 0] count ); always @(posedge clock) begin if (reset) count <= 0; else count <= count + 1; end endmodule
$ rake -f counter_rspec_runner.rake cver PROTOTYPE=1 Ruby-VPI: prototype has been enabled for test "counter_rspec" A resetted counter's value - should be zero - should increment upon rising clock edges A counter with the maximum value - should overflow upon increment Finished in 0.018199 seconds 3 specifications, 0 failures
$ rake -f counter_xunit_runner.rake cver PROTOTYPE=1 Ruby-VPI: prototype has been enabled for test "counter_xunit" Loaded suite counter_xunit_bench Started ... Finished in 0.040668 seconds. 3 tests, 35 assertions, 0 failures, 0 errors
Big ships turn slowly. -UnknownTraditional heavy-weight software development practices try to minimize unforeseen changes to a project plan by strictly adhering to precomputed requirements, schedules, and costs [44]. In contrast, agile software development practices embrace and adapt to unforeseen changes as and when they occur [44]. According to [3], these practices have a set of common, underlying characteristics that unify them under the "agile" name [7,page 213]:
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value: Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan That is, while there is value in the items on the right, we value the items on the left more.
For every tiny bit of functionality in the production code, you first develop a test that specifies and validates what the code will do. You then produce exactly as much code as will enable that test to pass. Then you refactor (simplify and clarify) both the production code and the test code.TDD plays a central role, along with pair programming and source code refactoring, in eXtreme Programming (XP)-one of the better known agile software development methodologies [19,page 43].
The older programming languages (Cobol, Fortran, Lisp) all came into existence as dedicated languages for solving problems in a certain area (respectively business processing, numeric computation and symbolic processing). Gradually they have evolved into general purpose languagesDespite this evolution, thorough studies of DSLs have only begun in recent years because "over and over again the need for more specialized language support to solve problems in well-defined application domains has resurfaced" [9].
Sometimes people jot down pseudo-code on paper. If that pseudo-code runs directly on their computers, it's best, isn't it? Ruby tries to be like that, like pseudo-code that runs. -Yukihiro MatsumotoRuby is a very high level, general purpose, object oriented programming language invented by Japanese computer scientist Yukihiro Matsumoto in the early 1990's [30,39]. It offers a harmonious balance between the functional and imperative styles of programming by blending the essence of Perl, Smalltalk, Eiffel, Ada, and Lisp [30] into one language. In addition, Ruby is considered to be an agile language because (1) it values programmer productivity over machine efficiency, (2) it aids interpersonal communication through its clear, expressive syntax and high readability, and (3) it is a dynamic language that not only embraces but facilitates change [22,pages 3-8].
You can add code to a running process. You can redefine methods on the fly, change their scope from public to private, and so on. You can even alter basic types, such as Class and Object.Some might argue that, due to dynamically linked libraries, C and C++ also have the ability to add code to a running process. However, this is just one aspect of anytime processing because such processing also allows you to alter the essential data types of the language as well. For example, imagine that when you loaded a particular dynamically linked library with C or C++, it redefined the int type as a linked list of char types. Now, any code that utilizes int would unknowingly be using a linked list! Such is the power granted by anytime processing.
The fascinating thing is that, in my experience, most well-written Ruby programs are already a DSL, just by nature of Ruby's syntax. -Jamis Buck [10,slide 22]Ruby is a viable platform for implementing DSLs because its syntax is unobtrusive enough to facilitate domain-specific expression without the need to write and maintain a custom compiler [11,10]. Furthermore, its strong meta-programming capability reduces the amount of code necessary to implement a DSL [10]. In addition to providing a means of structural expression for a DSL, Ruby enables general purpose programmability within the DSL itself [11]. To illustrate, imagine that SQL (see section A.5) was implemented as a DSL in Ruby. Now, you can use loops, libraries, and higher-order programming techniques within your SQL programs to solve complex problems with less effort.